您现在的位置是: 首页 > SEO学习 > 正文
Google法庭文件解读:SEO排名核心机密是什么?看这!
发布时间:2026-01-26 16:50:12 编辑:admin 浏览:308
- Hovers(鼠标悬停): 用户在你的标题上停顿了吗?犹豫了吗?
- Clicks(点击): 他们点进去了吗?
- Return(返回): 他们是不是马上又退回来了?
- Scrolls(滚动): 进页面后,他们滚动了吗?
- 当用户搜索“最好的跑鞋”时,他们倾向于点击哪些词?
- 他们喜欢长文章还是短视频?
- 他们看到什么标题会兴奋?
- 他们会测试发多少外链会触发 Spam Score 上升。
- 他们会测试堆砌多少关键词是安全的临界点。
- 他们会专门攻击那些 Spam Score 极低的“清白”老站,通过黑客手段注入垃圾内容,借壳上位。
- 热数据层: 需要极高新鲜度,爬虫可能几分钟来一次。
- 冷数据层: 没人看的内容,爬虫可能几个月才来一次。
- 保持内容的实效性。
- 定期更新旧文章。
- 获得持续的、新鲜的用户流量(这会反过来刺激爬虫更频繁地光顾)。
Google 被美国司法部(DOJ)逼到了墙角,法院判决要求其向竞争对手交出搜索数据的“核心机密”。Google 全球搜索负责人 Elizabeth Reid 紧急提交了一份声明,试图阻止这项判决,因为这相当于把Google 的“大脑”开源。
这份生命暴露了 Google 排名算法最深层的秘密:用户数据(User Data)。 接下来,我们尝试分析Google的这份法庭文件,看看能发现哪些 Google 极力隐藏的排名真相。
文件全文地址:https://storage.courtlistener.com/recap/gov.uscourts.dcd.223205/gov.uscourts.dcd.223205.1471.2.pdf
这一切是怎么发生的?
作为一名 SEO 从业者,我们习惯了猜测。我们猜权重,猜外链,猜算法。
但在 2026 年 1 月,一场针对 Google 的反垄断审判(United States v. Google LLC)又帮助我们的猜想更进一步:法院做出了最终判决,不仅认定 Google 非法垄断,还命令它做一件它死都不愿意做的事:把它的搜索索引(Index)和用户交互数据(User-Side Data)共享给竞争对手。
因此,Google 搜索副总裁Elizabeth Reid 在 1 月 16 日提交了一份紧急声明。她在文件中详细列举了为什么这项判决会给 Google 带来“不可挽回的伤害”。
这份充满了辩解的文件,再一次成为SEO的“泄密文档”。
秘密一:Google Glue——记录你一切行为的“全知之眼”
在文件中,Elizabeth Reid 提到了一个我们从未听说过的系统:GLUE。
这是一个极其庞大的统计模型系统。
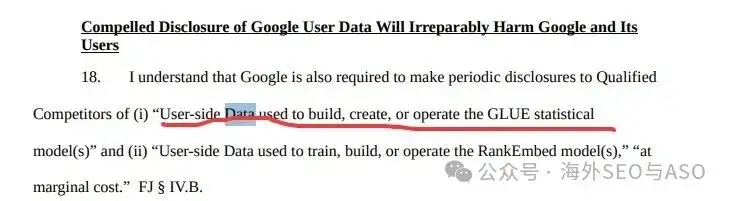
法院要求 Google 分享用于构建Glue 的数据。Reid 在声明第 20 段中无奈地承认了 Glue 到底记录了什么数据:
“Glue 模型的数据包括了过去 13个月的搜索日志。它不仅记录了用户的查询词(Query),还记录了页面上出现的每一个结果、每一个特征(Feature),以及它们的顺序。”
更重要的是,它记录了用户是如何与这些结果互动的。
这对 SEO 意味着什么?
以前我们常说“点击率(CTR)很重要”,或者“停留时间(Dwell Time)很重要”。
但 Glue 的曝光告诉我们,这不仅仅是“重要”。这是一个完整的、长期的用户行为数据库。
Google 并没有仅仅根据你的网页内容来排名。它在根据用户在过去 13 个月里对你(以及你竞争对手)的网页做出的所有微小动作来排名。

Glue 就是一个巨大的表格,记录了全球数十亿用户对每一个网页的真实投票。
如果你的网页内容很烂,但外链很强,也许你能骗过爬虫。但长期来讲,你骗不过 Glue。因为真实用户进去后的“失望行为”会被 Glue 忠实地记录下来,并在下一次更新中把你打入冷宫。
结论:你的排名,本质上是用户行为的历史记录。
秘密二:RankEmbed BERT——用点击数据训练的 AI 大脑
如果说 Glue 是记忆,那么RankEmbed 就是大脑。
文件中提到了另一个关键系统:RankEmbed BERT。
Reid 在声明中明确表示,Google使用“用户侧数据(User-side Data)”来训练、构建和运行 RankEmbed 模型。
在此之前的 SEO 圈子里,我们知道BERT 是用来理解自然语言的。我们以为它只是用来读懂“这个句子是什么意思”。
我们错了。
文件揭示,RankEmbed BERT 不仅仅是在理解语言,它是在根据用户的点击和查询数据进行训练。
这意味着什么?
这意味着 Google 的 AI 并不是在真空中学习“什么是好内容”。它是在观察人类。
RankEmbed 正在通过这些海量的点击流数据,不断微调排名的逻辑。它在学习“满足感”。
如果竞争对手拿到了这套数据,他们就能训练出自己的大语言模型(LLM),复刻出一个和 Google 一样懂人心的搜索引擎。这就是 Google 拼命要阻止数据分享的原因。

对于 SEO 来说,这是一个震耳欲聋的信号:不要再试图讨好机器算法了。机器算法本身就是在模仿人类的喜好。你直接讨好人类就行了。
秘密三:每个页面都有一个“垃圾分值”
在文件第 12 段,Reid 透露了一个让黑帽 SEO狂喜、让白帽 SEO 警惕的信息:
Google 的索引中,每一个 URL都被标记了一个“垃圾分值”。
这不是第三方工具(如 Moz)给出的那种估算值。这是 Google 官方的、专有的、内部的评分。
Reid 警告法院,如果这个分数泄露给竞争对手,或者被黑客拿到,那是灾难性的。
为什么?
因为一旦作弊者知道了哪些页面被标记为“低风险”,哪些被标记为“高风险”,他们就可以进行逆向工程。


这证实了一个长期的猜想:Google 对你的网站有一个整体的“信任度”或“健康度”评级。这个评级是动态的,且是绝对机密的。
如果你的网站流量突然腰斩,很有可能并不是你这一篇文章没写好,而是你的整站 Spam Score 触碰了红线。
秘密四:新鲜度(Freshness)的分层索引
Google 的索引不是平等的。
文件第 11 段揭示了 Google 的分层索引结构。
Google 根据内容需要被访问的频率,以及内容需要保持“新鲜”的程度,将网页分成了不同的层级。
Reid 担心,如果被迫分享“上次抓取时间(Time Last Crawled)”这一数据,竞争对手就能推断出 Google 的新鲜度信号。


这告诉我们:“更新频率”本身就是一个排名信号。
如果你希望你的文章排在前面,你不仅要写得好,还要让 Google 认为你属于“热数据层”。
如何做到?
一旦你掉入“冷数据层”,Google 就会减少抓取,你的排名和流量就会进入恶性循环。
结语:保持SEO 的一贯法则,用户满意度至上
看完这份长达 13 页的法律声明,作为一个 SEO 从业者,我感到的不是恐惧,而是兴奋。
因为规则变得前所未有的简单。
很多人迷失在技术细节里:H1 标签怎么写?Meta Description 多长?外链要 DoFollow 还是 NoFollow?
现在,Elizabeth Reid 用法律誓词告诉我们:Google 所有的核心机密——Glue、RankEmbed、Tiering——都在围绕一个东西转,那就是“用户数据”。
Google 并没有一个上帝般的算法来判断文章好坏。它只是一个极其聪明的统计员。它看着成千上万的人进入你的网站,然后看着他们满脸笑容地留下来,或者一脸嫌弃地退出去。
它把这些表情(数据)记在 Glue 系统里,喂给 RankEmbed 大脑,然后调整你的 Spam Score 和索引层级。
做对用户有价值的事,Glue 会看到的,RankEmbed 会记住的。
关键字词:google SEO